Hi. Yesterday, I did zpool scrubbing my first time, then I got
too many errors error about one disk, the pool is called tank and used to have 3 disks mirrored, I removed the disk that give errors and the pool has now 2 disks and sufficient replicas, but, today, I did a long test with smartctl but i got no errors, then why it give errors while scrubbing? Yesterday, I was not even be able to run smartctl -a on it (having input/output error) but after a reboot the problem was gone. Thanks in advance.
Code:
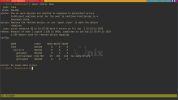
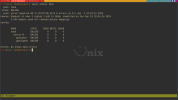
# smartctl -l selftest /dev/ada2
smartctl 7.4 2023-08-01 r5530 [FreeBSD 14.2-RELEASE amd64] (local build)
Copyright (C) 2002-23, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION ===
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Extended offline Completed without error 00% 5557 -
# 2 Extended offline Aborted by host 90% 5555 -
# 3 Short offline Completed without error 00% 5555 -
# 4 Short offline Completed without error 00% 3863 -
# 5 Short offline Completed without error 00% 2284 -
# 6 Short offline Completed without error 00% 0 -