Hello to all,
unfortunately I'm facing infamous messages when booting, when I'm trying to recover friend's NAS, which I installed last year.
It seems, it reaches up to stage 2, but gptzfsboot can't access the root pool.
Fortunately it served as a secondary server for archives, wasn't so heavily used and all user data are safely copied out for now.
I successfully booted USB stick with 13-2 release, mounted pool with altroot option on first attempt and read all the data.
Then I checked for some hardware errors, browsed trough old dmesgs and syslog messages at the filesystem, but found nothing.
All drives seems fine, no SMART incremented relevant counters, also no apparent glitches over few days with I/O load at my place.
I also tried fresh scrub without any encountered or corrected errors.
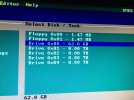
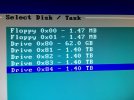
Hardware wise, it is older Gen 8 HP Microserver with four 8TB SATA drives from last year.
The pool consists of two mirrored vdevs (akin to conventional RAID 10). Pretty much standard setup from installer without any further customization.
Each drive has GPT table and three partitions - BIOS boot, geom mirror for swap and finally ZFS partitions up to end.
All datasets have common 128k block size.
As the server was in isolated network segment and was used just for seldom data offloading, it stayed on the same system version from the installation - 13.0-RELEASE-p10, no system upgrades with related snapshots were done after initial testing.
I tested clean unmount and export of pool from live environment, but it didn't help with boot.
I also tried to install fresh pmbr and gptzfsboot from latest 13.2-RELEASE, but it also didn't help, so I reverted back to original version.
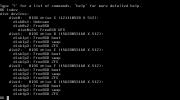
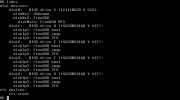
I tried to check boot environments, but it doesn't seem to be possible from live environment even at chrooted system.. I always ends at bectl: libbe_init("") failed.
There is of course zroot/ROOT/default, and it seems to be fine.
I dumped all relevant details, which came to my mind there.. (it's long so I've made a gist)

 gist.github.com
gist.github.com
As the error message is pretty much catch all I found and browsed maybe dozens of similar threads or questions for booting issues, but after several attempts, remedies mentioned there either doesn't seem to be applicable to my setup or won't help.
Of course I might overlooked something, so I will be glad for any further ideas.
I found only old issue with gtpzfsboot, which theoretically fits the system (BIOS boot only option, larger 8TB drives), but I'm not sure, if its applicable to me, especially if the system booted before.
 fa.freebsd.stable.narkive.com
fa.freebsd.stable.narkive.com
In normal situation, I'd already re-installed the server, but it's a bit frustrating form I haven't found any cause of the issue so far (hardware error or even my configuration mistake will be a relief") ).
).
Now I'm bit reluctant to repeat the same setup again with ZFS, as I don't have any clue, it it won't broke again.
Thanks,
Michal
unfortunately I'm facing infamous messages when booting, when I'm trying to recover friend's NAS, which I installed last year.
Code:
zio_read error: 5
ZFS: i/o error - all block copies unavailable
ZFS can't read MOS of pool zrootIt seems, it reaches up to stage 2, but gptzfsboot can't access the root pool.
Fortunately it served as a secondary server for archives, wasn't so heavily used and all user data are safely copied out for now.
I successfully booted USB stick with 13-2 release, mounted pool with altroot option on first attempt and read all the data.
Then I checked for some hardware errors, browsed trough old dmesgs and syslog messages at the filesystem, but found nothing.
All drives seems fine, no SMART incremented relevant counters, also no apparent glitches over few days with I/O load at my place.
I also tried fresh scrub without any encountered or corrected errors.
Hardware wise, it is older Gen 8 HP Microserver with four 8TB SATA drives from last year.
The pool consists of two mirrored vdevs (akin to conventional RAID 10). Pretty much standard setup from installer without any further customization.
Each drive has GPT table and three partitions - BIOS boot, geom mirror for swap and finally ZFS partitions up to end.
All datasets have common 128k block size.
As the server was in isolated network segment and was used just for seldom data offloading, it stayed on the same system version from the installation - 13.0-RELEASE-p10, no system upgrades with related snapshots were done after initial testing.
I tested clean unmount and export of pool from live environment, but it didn't help with boot.
I also tried to install fresh pmbr and gptzfsboot from latest 13.2-RELEASE, but it also didn't help, so I reverted back to original version.
I tried to check boot environments, but it doesn't seem to be possible from live environment even at chrooted system.. I always ends at bectl: libbe_init("") failed.
There is of course zroot/ROOT/default, and it seems to be fine.
I dumped all relevant details, which came to my mind there.. (it's long so I've made a gist)
Michal can't boot from zroot/ROOT/default
Michal can't boot from zroot/ROOT/default. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
As the error message is pretty much catch all I found and browsed maybe dozens of similar threads or questions for booting issues, but after several attempts, remedies mentioned there either doesn't seem to be applicable to my setup or won't help.
Of course I might overlooked something, so I will be glad for any further ideas.
I found only old issue with gtpzfsboot, which theoretically fits the system (BIOS boot only option, larger 8TB drives), but I'm not sure, if its applicable to me, especially if the system booted before.
unable to boot a healthy zfs pool: all block copies unavailable
In normal situation, I'd already re-installed the server, but it's a bit frustrating form I haven't found any cause of the issue so far (hardware error or even my configuration mistake will be a relief
). Now I'm bit reluctant to repeat the same setup again with ZFS, as I don't have any clue, it it won't broke again.
Thanks,
Michal
")